

GPU
Tổng quan về kiến trúc Ampere

Th5
Khi nói đến GPU, Nvidia là một chuyên gia hàng đầu. Với kinh nghiệm hoạt động từ năm 1993, Nvidia đã sản xuất ra một loạt các GPU chất lượng cao dành cho các chuyên gia và người dùng thông thường. Kiến trúc tuyệt vời của các bộ xử lý của họ là nguyên nhân chính đằng sau sự thành công của sản phẩm, đặc biệt là dòng chính của họ, GeForce. GPU của Nvidia đã vượt ra khỏi không gian chơi game, mở rộng sự hiện diện của mình trong lĩnh vực học sâu, trí tuệ nhân tạo (AI) và phân tích tăng tốc. Nvidia đã tiếp cận thị trường trung tâm dữ liệu từ mười năm trước, bắt đầu với việc sử dụng chip Fermi. Các phiên bản tiếp theo đã được tạo ra và công ty liên tục tung ra các GPU để đáp ứng nhu cầu không ngừng tăng về tốc độ xử lý nhanh hơn trong các trung tâm dữ liệu. Trong bài viết này chung tôi sẽ giới thiệu tổng quan về công nghệ Ampere trong GPU của Nvidia.
Kiến trúc Ampere của Nvidia
Cạnh tranh giữa các nhà sản xuất GPU rất khốc liệt, nhưng Nvidia không chần chừ để giành vị trí hàng đầu. Trên thực tế, Nvidia đã thống trị thị trường AI trong thập kỷ qua. Vào năm 2020, tin tức về GPU đầu tiên của Nvidia với công nghệ 7nm (8nm cho các bộ phận dành cho người tiêu dùng) với 54 tỷ transistor nằm trên một viên chip nhỏ đã gây sốt. Với tên mã Ampere, theo tên của nhà toán học người Pháp André-Marie Ampère, kiến trúc bộ xử lý của Nvidia nâng cao đáng kể so với các phiên bản trước đó là Turing và Volta, hứa hẹn mang đến nhiều chức năng hơn, hiệu suất tốt hơn và tiêu thụ năng lượng thấp hơn.
Ampere là cơ sở cho thế hệ thứ hai của GPU RTX của Nvidia, dòng RTX 30 series, và được cho là gấp đôi tốc độ so với các đối tác của dòng RTX 20 series. Kiến trúc Ampere cũng là nguồn lực cho GPU trung tâm dữ liệu Nvidia A100.
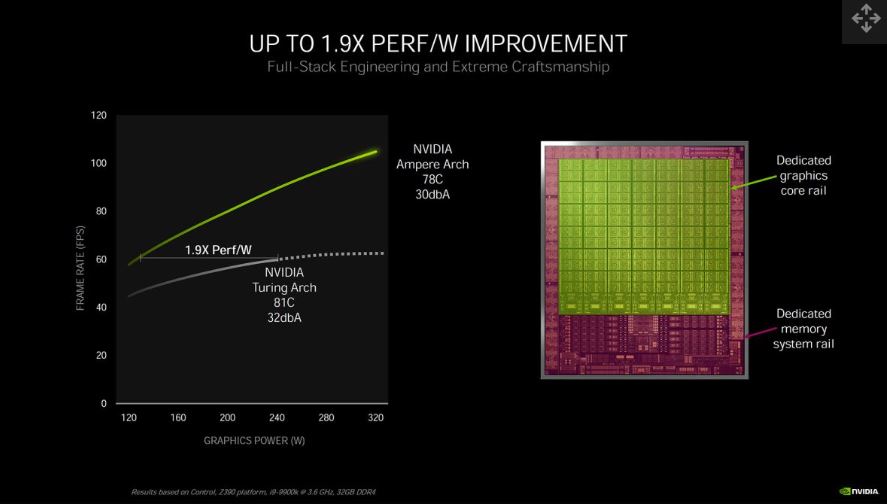
Thông số kỹ thuật của Ampere
Ampere là GPU 7nm/8nm đầu tiên của Nvidia, là thế hệ thứ hai của công nghệ ray tracing dành cho người tiêu dùng, và có thế hệ thứ ba của nhân tensor. Ampere là kiến trúc cơ bản của các GPU GA100, GA102 và GA104 được tích hợp trong GeForce RTX 3090, RTX 3080, RTX 3070 và gần đây nhất là RTX 3060. Nvidia cũng dự định phát hành RTX 3050 trong những tháng tiếp theo. Trong khi đó, GPU GA100 dành cho doanh nghiệp cung cấp khả năng tính toán gấp 20 lần so với các thế hệ trước đây của GPU trung tâm dữ liệu. Dưới đây là tổng quan về GPU chuyên nghiệp và GPU tiêu dùng dựa trên Ampere của Nvidia:
GPU |
GA100 |
GA102 |
GA102 |
GA104 |
|---|---|---|---|---|
| Card đồ họa | Nvidia A100 | GeForce RTX 3090 | GeForce RTX 3080 | GeForce RTX 3070 |
| Quy trình (nm) | TSMC N7 | Samsung 8N | Samsung 8N | Samsung 8N |
| Transistor (tỷ) | 54 | 28.3 | 28.3 | 17.4 |
| Kích thước chip (mm^2) | 826 | 628.4 | 628.4 | 392.5 |
| Cấu hình GPC | 8×16 | 7×12 | 6×12 | 6×8 |
| SMs | 108 | 82 | 68 | 46 |
| CUDA Cores | 6912 | 10496 | 8704 | 5888 |
| RT Cores | None | 82 | 68 | 46 |
| Tensor Cores | 432 | 328 | 272 | 184 |
| Boost Clock (MHz) | 1410 | 1700 | 1710 | 1730 |
| Tốc Độ VRAM (Gbps) | 2.43 | 19.5 (GDDR6X) | 19 (GDDR6X) | 14 (GDDR6) |
| VRAM (GB) | 40 (48 max) | 24 | 10 | 8 |
| Độ rộng bus | 5120 (6144 max) | 384 | 320 | 256 |
| ROPs | 128 | 112 | 96 | 96 |
| TMUs | 864 | 656 | 544 | 368 |
| GFLOPS FP32 | 19492 | 35686 | 29768 | 20372 |
| RT TFLOPS | N/A | 69 | 58 | 40 |
| Tensor TFLOPS FP16 (sparsity) | 312 (628) | 143 (285) | 119 (238) | 81 (163) |
| Băng thông (GB/s) | 1555 | 936 | 760 | 448 |
| TBP (watts) | 400 (250 PCIe) | 350 | 320 | 220 |
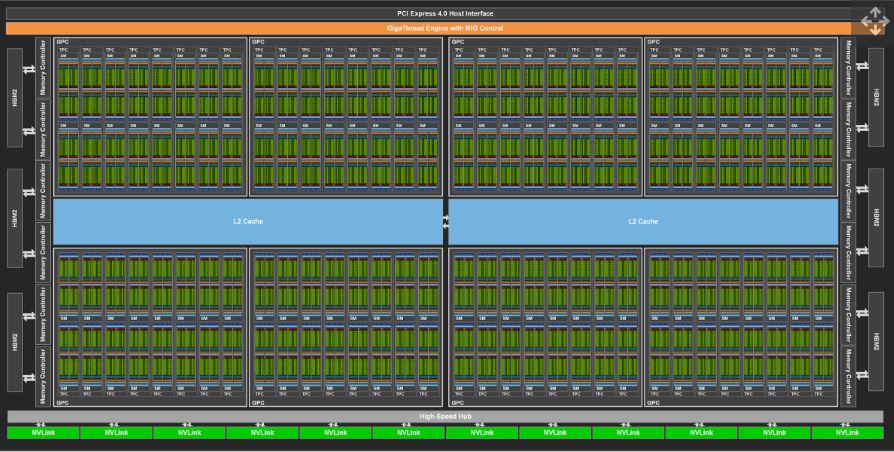
Nvidia A100
Nvidia A100 là GPU đầu tiên sử dụng kiến trúc Ampere. Chip dành cho doanh nghiệp này hướng đến trung tâm dữ liệu và được thiết kế cho các nhiệm vụ tập trung GPU như học sâu và trí tuệ nhân tạo. Được xây dựng bằng quy trình 7nm của TSMC, nó chứa một lượng transistor lớn lên đến 54 tỷ. Nó đã vượt qua các thế hệ trước của GPU doanh nghiệp với sự tăng gấp 20 lần về hiệu suất, với 6.912 lõi CUDA, 432 đơn vị ánh xạ texture, 160 ROPs, tensor cores thế hệ thứ ba và bộ nhớ VRAM 40GB với băng thông đạt tối đa 1.6TB/giây. DGX A100 là hệ thống trí tuệ nhân tạo đầu tiên trên thế giới với một cụm gồm tám A100 và mức giá cao gấp đôi, lên tới 199.000 USD.
Dòng GeForce RTX 30 Series
Ngoài việc thống trị thị trường doanh nghiệp, Nvidia luôn có sự quan tâm đến người tiêu dùng, đặc biệt là game thủ và nhà sáng tạo. Kiến trúc Ampere cũng được áp dụng vào các card đồ họa tiêu dùng của Nvidia. Thế hệ thứ hai của GeForce RTX mang theo các GPU dựa trên Ampere, nâng cao hiệu suất gấp đôi so với thế hệ trước đó.
Về mặt nhiều khía cạnh, Ampere có công suất xử lý gấp đôi Turing. Nó đã gấp đôi hiệu suất shader của Turing với gấp đôi số lượng lõi FP32 CUDA. Cụ thể, nó có 30 Shader-TFLOPS, gấp 2,7 lần so với Turing chỉ có 11 Shader-TFLOPS. Tương tự, Turing có 89 Tensor-TFLOPS, trong khi Ampere có hơn gấp đôi với 238 Tensor-TFLOPS. Không quên tỷ lệ lõi Ray Tracing, Ampere đạt 58 RT-TFLOPS, nhanh hơn gấp 1,7 lần so với Turing với 34 RT-TFLOPS. Để đảm bảo hoạt động nhanh hơn, chip Ampere kết nối với bộ nhớ G6X của Micron – bộ nhớ nhanh nhất thế giới.
Dòng RTX 30 series được sản xuất bằng quy trình sản xuất tùy chỉnh Samsung 8N với 28 tỷ transistor cho GPU GA102 và 17 tỷ transistor cho GPU GA104. Các card đồ họa Ampere này có băng thông bộ nhớ lớn hơn so với các phiên bản trước đó và hỗ trợ công nghệ DLSS 2.0 mới nhất, mang lại trải nghiệm chơi game tốt hơn và đáng tin cậy hơn.
Kết Luận
Ampere là kiến trúc GPU mới của Nvidia, được sử dụng trong dòng A100 dành cho doanh nghiệp và dòng GeForce RTX 30 series dành cho người tiêu dùng. Nó mang lại nhiều cải tiến về hiệu suất, chức năng và tiêu thụ năng lượng so với các thế hệ trước đó, đồng thời cung cấp hỗ trợ cho ray tracing và công nghệ trí tuệ nhân tạo.